
Créez plusieurs flux pour un nombre illimité de cas d'usage
Data Flow est composé d'une interface utilisateur de type point & click qui vous permettra de créer différents flux pour partager des données granulaires dans le bon format aux bonnes parties prenantes.
Activer l'option Data Flow
Data Flow est une option payante qui peut être activée sur votre organisation.
Pour accéder à Data Flow, contactez votre Account Manager via votre administrateur ou contactez notre centre support.
Interface
Création d'un nouveau flux de données
Les flux peuvent être configurés directement à partir de notre interface Exports sous forme d'exports planifiés (Menu > Configuration > Exports).
Une interface dédiée vous permettra de configurer vos flux de données. Vous pourrez configurer les aspects suivants de vos flux de données :
Une interface dédiée vous permettra d’effectuer cette configuration d’exports. Vous pourrez entre autres :
-
Multisite: Sélectionner un site ou l’ensemble des sites auxquels vous avez droit d’accéder.
-
Choix de propriétés : Choisir les propriétés composant votre export (standard et custom).
-
Format : Choisir le type de séparateur et le format d’export entre CSV, JSON et PARQUET.
-
Planification : Choisir la fréquence d’export – 15, 30 ou 60 minutes.
-
Stockage : Choisir l’emplacement de l’export, sFTP, Amazon S3, GCP (Azure par la suite).
Accéder à l'interface Data Flow - Exports planifiés
Pour vous connecter à l'interface de Data Flow, rendez-vous sur l'app Export :
Vous serez ensuite en capacité de créer des exports planifiés Data Flow.
Création d'un export planifié Data Flow
Cliquez sur "Créer un export Data Flow" pour créer un nouveau flux de données.
Vous accéderez ensuite au paramétrage de votre flux d'export qui se présente sous forme de 2 étapes très simples :
ETAPE 1 : Que voulez-vous inclure dans votre export ?
|
|
Le périmètre de votre export Avez-vous besoin d'informations concernant tous les sites web de votre organisation ? Ou seulement d'un ou plusieurs de vos sites internet ? |
|
|
Activation du filtre privacy Vous avez la possibilité d'activer le filtre privacy afin de respecter la règlement en vigueur. Ce filtre privacy activé vous permet d'écarter de vos exports les données non-consenties. Si vous décidez de ne pas activer ce filtre privacy, après réception de toutes les données Piano Analytics, vous devrez si besoin purger une partie de vos données reçues afin de respecter la règlement en vigueur dans votre pays. Le filtre privacy est basé sur "visitor_privacy_consent = false". |
|
|
Les données dont vous avez besoin d'exporter Voulez-vous exclure les données non-consenties ? Voulez-vous exporter la totalité de vos propriétés actuelles et futures ? Ou seulement certaines propriétés ?
|
ETAPE 2 : Quelles sont les caractéristiques de votre export ?
|
|
Nom du flux d'export Nommez votre flux d'export
|
|
|
Choix du format d'export Choisissez votre format d'export : CSV, JSON ou Parquet. La configuration change automatiquement pour chaque format que vous sélectionnez. Veuillez noter que le format JSON est plus exactement du NDJSON (Newline Delimited JSON). |
|
|
Fréquence d'export & enregistrement
=> missinglefile: false => Aucun problème. => missinglefile: true => Un fichier est manquant. |
Configuration des connexions Amazon S3
La configuration des connexions Amazon S3 est un processus simple.
Pour commencer, sélectionnez "Amazon S3" comme type d'envoi lors de la configuration de votre export.
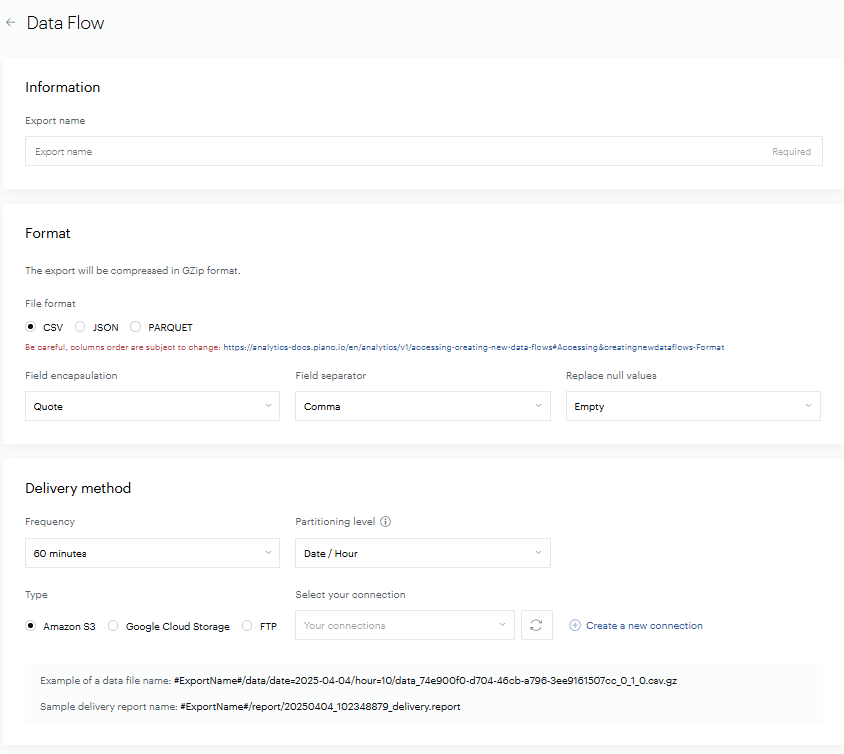
Sélectionnez ensuite "Créer une nouvelle connexion" :
La fenêtre de configuration suivante s'affiche. Afin de pouvoir exporter les fichiers nous avons besoin des informations suivantes :
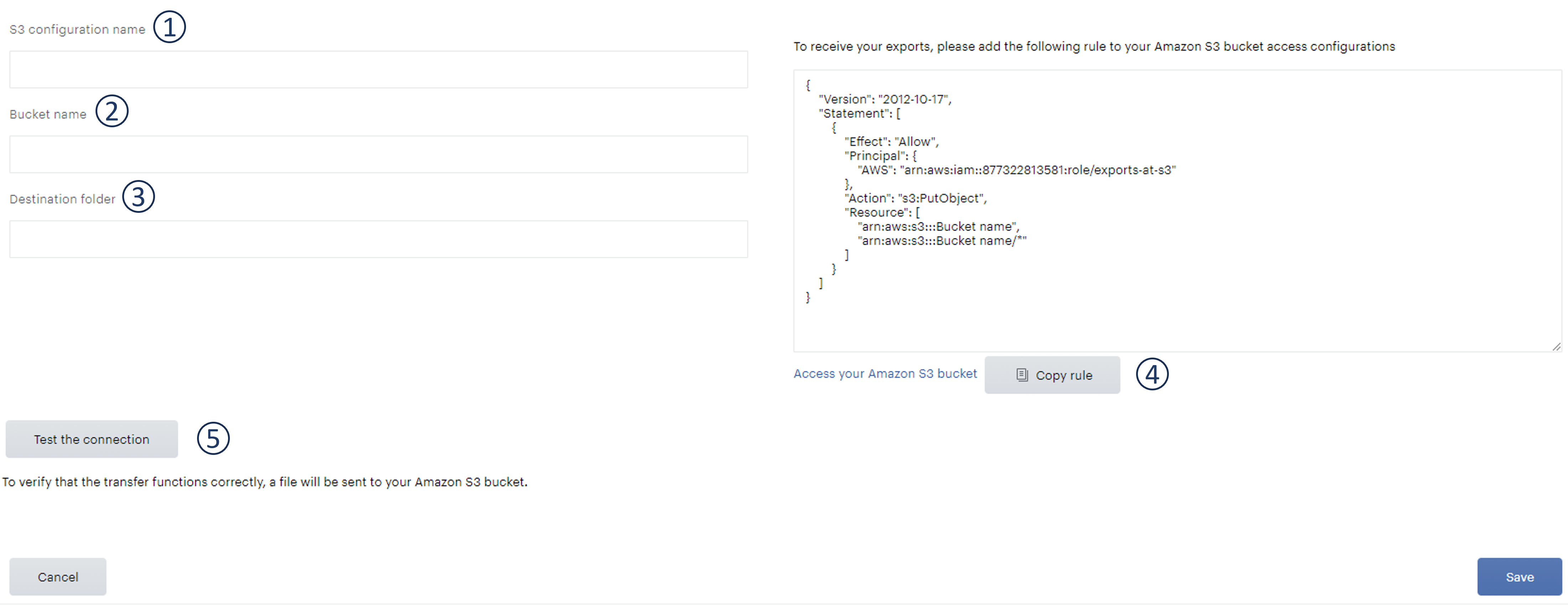
-
Nom de la configuration S3 - les informations présentes ici sont à titre de référence. Cela vous permettra de trouver et de modifier votre connexion parmi les autres connexions Amazon S3 que vous avez configurées avec Piano Analytics.
-
Nom du Bucket - Nous avons besoin d'informations concernant le nom de votre Bucket Amazon S3. Il s'agit d'un identificateur unique et propre à votre bucket. Cela nous permettra d'envoyer les fichiers au bon emplacement.
-
Dossier de destination - Si vous souhaitez envoyer les exports à un endroit autre que le dossier principal du Bucket, vous pouvez spécifier le chemin d'accès ici, les sous-dossiers doivent être séparés par "/".
-
Règle de configuration d'accès - L’accès aux bucket de stockage S3 du client se fait à travers une authentification par rôles AWS. Piano Analytics fournira au client l’ARN d’un rôle à autoriser sur son bucket pour permettre l’accès en écriture afin d’y déposer les fichiers. Le client à la charge mettre en place la « Bucket Policy » donnant l’accès au Rôle Piano Analytics.
-
Tester la connexion - Lorsque vous appuyez sur le bouton "tester la connexion", nous enverrons un fichier sur votre Bucket Amazon S3 qui nous permettra de confirmer que les informations que vous nous avez fournies sont correctes et que la connexion a été établie correctement.
et sauvegardez !
Lorsque vous revenez sur la configuration, cliquez sur : 
Configuration des connexions FTP et sFTP
La configuration des connexions FTP ou sFTP est un processus simple.
Sélectionnez "FTP" comme type d'envoi lors de la configuration de votre export.
Ensuite, sélectionnez "Créer une nouvelle connexion" :
La fenêtre de configuration suivante s'affiche. Afin de connaitre les droits et la destination où Piano Analytics doit exporter les fichiers, nous avons besoin des informations suivantes :
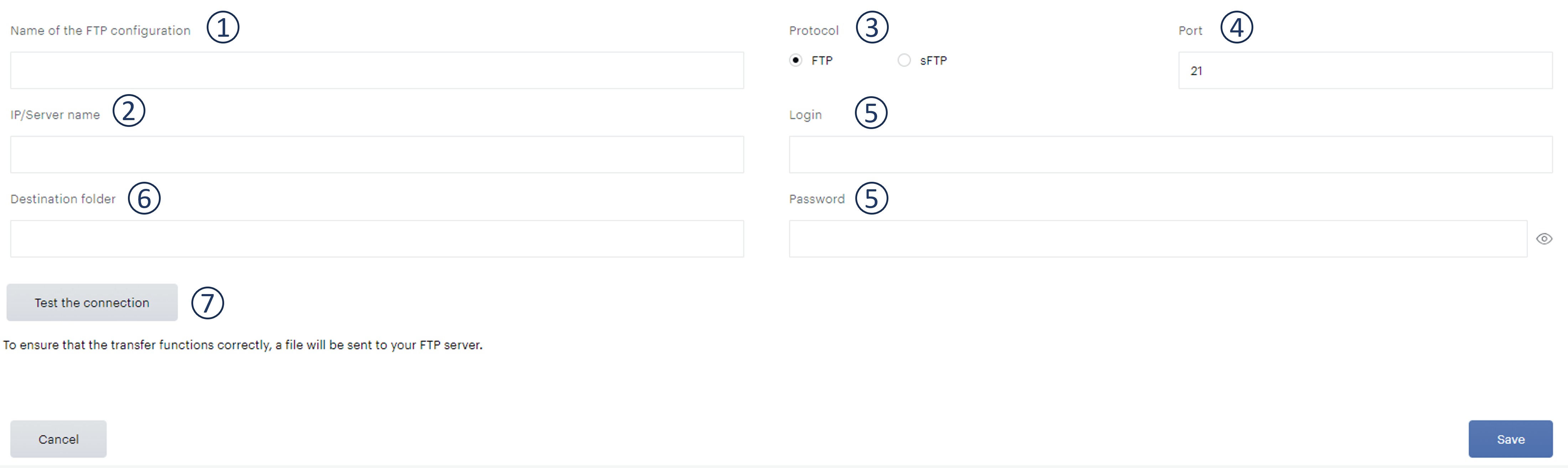
-
Nom de la configuration FTP - les informations demandées ici sont à titre de référence. Cela vous permettra de trouver et d'éditer votre connexion parmi les autres connexions FTP que vous avez configuré avec Piano Analytics.
-
IP/Nom du serveur - Nous avons besoin d'informations concernant l'adresse IP ou le nom du serveur où se trouve votre serveur FTP.
-
Protocole - dans cette section, vous pourrez spécifier le protocole que vous souhaitez utiliser : FTP ou sFTP
-
Port - Dans cette section, vous pouvez spécifier le port que vous souhaitez utiliser.
-
Identifiant & Mot de passe - Pour que nous puissions exporter le fichier, nous avons besoin d'un identifiant & mot de passe valide avec suffisamment de droits d'accès pour pouvoir pousser les accès.
-
Dossier de destination - Si vous souhaitez envoyer les exportations à un endroit autre que le dossier principal du bucket, vous pouvez spécifier le chemin d'accès ici, les sous-dossiers doivent être séparés par "/".
-
Tester la connexion - lorsque vous appuyez sur le bouton "tester la connexion", nous enverrons un fichier au FTP qui nous permettra de confirmer que les informations que vous nous avez fournies sont correctes et que la connexion a été établie correctement.
et sauvegardez!
Vous souhaitez autoriser des adresses IPs?
Vous pouvez contacter notre centre support afin de récupérer les adresses IPs à autoriser de votre côté.
Nous vous recommandons fortement de préférer l'envoi S3 à l'envoi FTP : ce dernier est un protocole vieillissant qui ne permet pas des transferts rapides de fichiers. Nous vous proposerons prochainement des envois vers Google Cloud Platform et Microsoft Azure.
Si vous être dans l'obligation d'utiliser un envoi vers FTP, nous vous conseillons alors d'utiliser une fréquence d'envoi à 15 ou 30 minutes qui limitera la taille des fichiers à envoyer.
Configuration des connexions GCP
L’envoi de fichiers via connexion GCP est disponible, mais il vous faudra en faire la demande directement au support. Nos consultants vous guideront dans le process pour configurer vos exports.
Planification
Le système de planification des exports Data Flow ne se base pas sur des périodes complètes. A chaque tour de boucle (toutes les 15, 30 ou 60 minutes), toutes les nouvelles données insérées en base depuis le dernier export sont extraites. Dans notre nouvelle chaîne de traitement, la NDF, c'est grâce à ce système que nous avons l'assurance de vous envoyer l'exhaustivité de vos événements.
Les exports de flux de données sont valables pendant 12 mois, ils expireront après ce délai. Vous recevrez une notification un mois avant la date d'expiration par email vous rappelant de prolonger l'export.
Disponibilité des données
Certaines données ne seront pas disponibles sur Data Flow. La raison est simple : ces propriétés sont calculées "à la volée" et ne sont pas stockées ou ce sont des propriétés "incertaines". Par exemple, nous ne savons pas à l'avance si une visite sera considérée comme un "rebond". De ce fait, la propriété "visit_bounce" ne peut pas être proposée dans Data Flow.
Partitionnement
Data Flow inclut une nouvelle fonctionnalité : le partitionnement. Etant donné que les fichiers ne portent pas sur des périodes complètes, le partitionnement vous permet d'organiser vos fichiers selon la période qu'ils contiennent. Cette période est basée sur la date UTC de collecte des données (propriété hit_time_utc).
Vous avez la possibilité de choisir votre niveau de partitionnement :
-
Date
-
Date / Heure
-
Date / Heure / Demi-heure
-
Date / Heure / Quart d'heure
Prenons un exemple concret. Imaginons que vous ayez créé un export horaire avec un partitionnement à niveau Date / Heure. L'export se nomme myExport, il est envoyé dans un dossier myFolder.
Le contenu de la table au moment de l'extraction est le suivant :
|
Hit_time_utc |
event_id |
... |
|
08/04/2021 10:58:14 |
abcdefghij |
... |
|
08/04/2021 10:59:27 |
fjezoijznczeufh |
... |
|
08/04/2021 11:00:28 |
hezihigiregie |
... |
|
08/04/2021 11:01:45 |
jeijgirejrejgjei |
... |
Les données sont à cheval sur deux heures, elles vont donc être réparties dans des fichiers différents.
Dans le cas d'un envoi S3 :
myFolder/myExport/data/date=2021-04-08/hour=10/data_36_019ac5aa-3252-4738-0000-03d5ba4052ba_001_0_0.csv.gz
et
myFolder/myExport/data/date=2021-04-08/hour=11/data_36_019ac5aa-3252-4738-0000-03d5ba4052ba_001_0_0.csv.gz
Le premier fichier contiendra les événements extraits dont la propriété hit_time_utc est comprise entre 10:00:00 et 10:59:59, le deuxième ceux dont la propriété hit_time_utc est comprise entre 11:00:00 et 11:59:59. Si au prochain tour de boucle il y a de nouvelles données comprises entre 11:00:00 et 11:59:59, de nouveaux fichiers seront créés dans le dossier /hour=11/.
Dans le cas d'un envoi (s)FTP, la logique est la même, seule la nomenclature change. Nous ne pouvons pas créer dynamiquement des dossiers, donc ce sont les noms de fichiers eux-mêmes qui portent l'information de période :
myFolder/myExport_2021-04-08_10_data_36_019ac5aa-3252-4738-0000-03d5ba4052ba_001_0_0.csv.gz
myFolder/myExport_2021-04-08_11_data_36_019ac5aa-3252-4738-0000-03d5ba4052ba_001_0_0.csv.gz
Format
Une fois votre flux créé, vous recevrez directement sur votre serveur Amazon S3/sFTP les fichiers générés par Data Flow. Chaque fichier généré est compressé au format GZ. Les noms de fichiers incluent une nomenclature gérée par Snowflake repérable sur la fin du nom de fichier de la façon suivante :
data_#GUID#_#NumérotationSnowFlake#.format
Vous trouverez des exemples dans le paragraphe précédent.
Afin d'accélérer les traitements, Snowflake exécute la requête par parties sur différentes machines, donc pour un même export généré à un instant T, vous pourrez recevoir plusieurs fichiers.
Important :
Concernant les exports au format CSV, nous vous recommandons de ne pas vous baser sur les index des colonnes mais sur leurs entêtes : nous ne pouvons garantir d'ordre fixe d'affichage des propriétés.
Dans les exports au format JSON, les propriétés avec une valeur vide n'apparaitront pas pour l'événement concerné.
Rapport de livraison
Après chaque génération de fichiers sur votre bucket Amazon S3 /GCP/ sFTP, vous recevrez en complément un fichier ".report" qui contiendra la liste des noms de fichiers générés que vous venez de recevoir.
Si vous avez reçu un fichier dont le nom n'est pas contenu dans un rapport de livraison, c'est que ce fichier n'est pas complet, il faut donc l'occulter.
La réception de ce rapport de livraison atteste de la bonne génération et livraison des exports sur une période donnée.
Ex : à 10h20 UTC une génération est lancée, il en résulte trois fichiers :
-
myFolder/myExport/data/date=2021-10-31/hour=09/min=45-60/data_019ac5aa-3252-4738-0000-03d5ba4052ba_001_0_0.csv.gz
-
myFolder/myExport/data/date=2021-10-31/hour=10/min=00-15/data_049fc5da-3372-8338-1200-08f7bc4801cz_001_0_0.csv.gz
-
myFolder/myExport/data/date=2021-10-31/hour=10/min=00-15/data_049fc5da-3372-8338-1200-08f7bc4801cz_002_0_0.csv.gz
Une fois que ces trois fichiers ont été intégralement déposés dans votre bucket S3 /GCP/ votre sFTP, un rapport de livraison nommé #timestamp#_delivery.report vous est envoyé, contenant ces trois mêmes noms de fichiers, et atteste donc que vous pouvez récupérer leur contenu en toute sérénité.
Génération d'historique
Les exports de génération d'historique ou de régénération d'une date passée se baseront sur le même niveau de partitionnement que votre export de production. La régénération pourra se faire dans un dossier distinct.
Pour pouvoir générer de l'historique d'un jour X à un jour Y et minimiser le risque de doublons ou de trous de données, voici la marche à suivre :
-
Si ce n'est pas déjà fait, mettre l'export en production avec la fréquence désirée
-
à Y+1, vous devez supprimer les données que vous avez ingérées dans votre base de données avec une requête comme suit : DELETE * FROM #matable# WHERE hit_time_utc < Y+1
-
Nos équipes AT Internet en interne créent un ticket de génération d'historique à l'équipe Exports en précisant :
-
Votre compte client sur lequel l'export de production a été créé
-
Le nom de votre export
-
La période exacte à régénérer (X à Y)
-
A savoir
Il est possible que des exports de production contiennent parfois des doublons. Ce n'est pas inhérent à Data Flow mais à la collecte des données. Ces doublons apparaîtront également dans Data Query sur la journée en temps réel. Les doublons sont supprimés à J+1 dans la table de données consolidées, mais cela n'a donc pas d'impact sur les fichiers Data Flow déjà consommés.
En cas de retard de temps réel, les événements non inclus dans un fichier seront inclus dans les fichiers suivants, toujours en se basant sur leur date de collecte. Auquel cas, on peut avoir des fichiers plus légers que de coutume sur une période puis des fichiers plus lourds sur la période suivante.